How Product Marketing Teams Scale Without Review Bottlenecks

7 people can touch one product marketing draft before it ships. That's not a quality system. It's a symptom.
If you're trying to build a governance blueprint for multi-writer product marketing scale, you've probably felt this this week: the writer got the structure mostly right, PMM rewrote the positioning, someone fixed the product claims, demand gen softened the CTA, and now the piece is late again.
Demand-gen content execution platform is a governed content operations system that turns approved strategy, product truth, and audience context into repeatable demand-generation output by enforcing the same marketing rules across planning, creation, review, and distribution. Unlike AI writing tools or freelance content capacity, a demand-gen content execution platform keeps strategic control inside the workflow instead of asking senior marketers to manually re-approve every asset.
This category showed up because the old model stopped holding together. GEO changed the bar. It's not enough to publish decent content anymore. You need content that sounds like one company, says the same thing across formats, and stays accurate when five different people touch it.
Key Takeaways:
- Review loops are usually a system problem, not a writer problem
- The Strategy-Execution Trade-off is the real enemy in multi-writer product marketing
- More writers, agencies, and better prompts still inherit the same context gap
- GEO makes inconsistency more expensive because scattered signals weaken brand visibility
- A real governance blueprint starts upstream, before drafting begins
- Governed execution means strategy, product truth, and audience rules travel with every asset
Why The Review Loop Keeps Breaking Product Marketing Teams
Product marketing review cycles break because most teams use review as a substitute for operational control. That works when one strong writer carries the context. It starts to fail the moment multiple contributors need to ship from the same strategy.

Review Debt Usually Starts As System Debt
Most teams call it review debt because that's what it looks like on the surface. Drafts come in off-message. Claims are slightly off. The CTA sounds like generic marketing mush. Then a senior person steps in and fixes it. Again. And again.
But the real issue isn't that people can't write. It's that strategy lives in scattered places: a positioning deck, a launch memo, a few Slack threads, a product doc somebody swears is current, and a founder's head. So every piece has to be reconstructed from scratch. That's not editing. That's manual system repair.
I've seen this pattern enough times that it feels predictable. At first, leaders think the answer is tighter review. Then they think the answer is a better freelancer. Then a better prompt. Then maybe another PMM. All reasonable. None of them fix the root cause if the workflow still depends on one person being the final translator of what the company means.
A review queue is not a strategy layer. It's just where missing context goes to die.
Multi-Writer Scale Fails The Moment Context Stops Travelling
Back in 2012-2016 I ran a website that hit 120k unique visitors a month. We had 80 regular contributors and more than 300 guest contributors over time. What made that work wasn't just volume. It was that depth and breadth had enough structure underneath them that the machine kept moving.
The lesson wasn't "just get more writers." That's the wrong lesson. The real lesson was that scale only works when contributors know what kind of piece they're writing, what angle matters, and what good looks like before they start. Once that breaks, output starts looking wide but weak.
You see the same thing in product marketing teams. Writer one frames the feature for a buyer. Writer two frames it like a help doc. Writer three turns it into thought leadership. None of them are technically wrong. But together, they create narrative drift. The company starts sounding like three different companies.
For agencies, it's even sharper. You aren't just managing one context gap. You're managing one per client, per product line, sometimes per persona. That's why multi-writer production often feels fine at 4 assets a month and messy at 20. The hidden threshold is usually around the point where no single reviewer can keep all the context in their head anymore.
If you want to see what governed execution looks like when the review burden starts dropping, you can request a demo.
GEO Punishes Inconsistency More Than It Punishes Slow Output
GEO changed what good content has to do. It has to work for humans, search engines, and LLMs. That's a different standard than "this blog post is pretty solid."
LLMs don't just look at one page. They synthesize patterns. They look for clear product definitions, audience specificity, stable terminology, and a repeated point of view across lots of content. That's why scattered messaging is now more expensive than a slower publishing schedule. If half your library says one thing and the other half says a softer, vaguer version, you're training the market to misunderstand you.
Worth noting, this is one place where volume-first advice starts to fall apart. If your content library is under 50 pages, inconsistency hurts less because the signal set is small. Once you pass 100 to 150 pages across blog, product, buyer education, and social, inconsistency starts compounding. LLM visibility is a pattern-recognition problem. Pattern recognition hates drift.
So the problem isn't content velocity on its own. It's unmanaged velocity. Different thing.
Why More Writers, Better Prompts, And Bigger Budgets Still Miss The Point
The bottleneck in product marketing scale isn't content creation. It's strategic intent surviving contact with production. That's why the usual fixes improve speed for a bit, then stall out in the same place.
Prompting Makes Drafts Faster But Keeps Judgment Manual
Prompting is useful. We all know that. I wouldn't argue otherwise. For ad hoc work, rough ideation, first passes, sure. It can save time.
But prompting treats each output like a standalone event. Demand gen and product marketing are not standalone work. They are systems of repetition. The same product truth, same audience framing, same category argument, same approved boundaries, pushed across many assets over time. Prompting doesn't hold that together. People do.
That's the trap. It feels like you've sped up production, but you've actually pushed more judgment onto reviewers. Somebody still has to decide if the claim is accurate. Somebody still has to notice if the positioning drifted. Somebody still has to catch whether this draft is talking to a Head of Product Marketing or an SEO lead like they're the same person.
We ran into a version of this years ago with founder-led content. Recording videos and transcribing them was faster. No question. But the structure SEO needed wasn't there, and topic discovery wasn't disciplined enough either. So the output had ideas, but not enough shape to rank or compound. Faster input. Weak system.
If you're using prompts for reactive content or experimentation, fair point, that can be valid. If you're trying to run multi-writer scale that way, you're quietly signing up your senior team to become the quality layer forever.
More Capacity Doesn't Fix Narrative Drift
Anecdote lead here, because this one is real. At PostBeyond, I could crank out 3 to 4 high quality blog posts a week when I was the one writing. As the team grew, our writer didn't have all the context and expertise I had, so output took longer and quality dipped. At the same time, I had less time to write because I was in meetings and managing the team.
That pattern shows up all over SaaS. Hiring capacity adds output potential, but it also multiplies handoffs. And handoffs are where things go wrong. One person knows the category frame. Another knows the product edge cases. Another knows which use case actually closes deals. If those don't travel together, then every new contributor adds throughput and drift at the same time.
Agencies inherit the exact same problem. Sometimes worse. People assume an agency issue is a talent issue. Often it's a translation issue. The client believes the strategy is documented. The agency gets the docs, interviews stakeholders, builds a process, and still misses the sharpest parts of the story because those lived in side comments, not operating rules.
So no, hiring more writers isn't wrong. Agencies aren't wrong. Freelancers aren't wrong. They just don't solve the hidden system problem by themselves.
The Real Choice Is Managed Context Or Manual Cleanup
Most teams think the choice is speed versus quality. That's the Strategy-Execution Trade-off talking. It sounds reasonable because it's been true in most content workflows for years.
But the more useful frame is this: unmanaged execution versus governed execution. That's the actual split.
If strategic context is unmanaged, then quality depends on review. If strategic context is governed, quality starts earlier. Not with a style doc in a folder. With operating rules tied to production. What claims are approved. Which audience frame applies. What the product is and isn't. What the company believes about the market. What kind of content should exist in the first place.
That's also why this article is really a governance blueprint for multi-writer scale, not a staffing guide. The difference matters. Staffing changes who touches the work. Governance changes what follows the work.
And that's the pivot most teams miss.
What Fragmented Execution Actually Costs You
Fragmented execution costs more than delayed publishing. It creates compounding waste across time, trust, visibility, and budget. The ugly part is that these costs rarely show up in one dashboard.
Every New Contributor Creates Another Context Leak
One writer misunderstanding a feature is annoying. Five contributors interpreting the same product differently is a pattern failure.
Let's pretend you have one PMM, two content writers, one freelance editor, one SEO person, and one agency partner supporting launches. If each person misses just 10% of the strategic context, you don't end up 10% off. You end up with a messy chain of small distortions. The feature gets framed a little too broadly. The audience gets flattened. The differentiator gets softened. The final piece sounds plausible, but not sharp.
This is where people underestimate the cost. Context loss compounds faster than word count. A 1,500-word article with weak product framing can do more damage than no article at all because now the wrong message is published, distributed, and reused.
I saw a version of this at a company with strong SEO performance. We ranked really well on Google for a lot of topics. But the content sat too far away from the solution. Great traffic. Weak demand-gen alignment. We had content about adjacent problems, but not enough connective tissue back to the product and category. So the machine generated attention, not movement.
Traffic without narrative fit is expensive decoration.
Leaders Become The Integration Layer, And That's The Real Tax
The editing loop gets expensive when senior people stop reviewing and start reintegrating broken context. That's a different job.
A VP Marketing opens a draft and rewrites the intro because the writer used the wrong market frame. Then they fix a product claim because the feature boundary isn't clear. Then they rework the CTA because demand gen needs it tighter. Then legal flags wording. Then the writer revises. Then the PMM checks it again. By the time it ships, the leader has spent 45 minutes to 90 minutes doing system stitching on one asset.
Use a threshold here. If a senior reviewer spends more than 20 minutes correcting positioning and product truth per draft, your issue is upstream. If that happens on 8 assets a month, you're burning 160+ minutes on just one type of repair. If it's 20 assets, you're into 6 to 10 hours a month of high-value time doing integration work that should've been handled before the first draft existed.
That one hurts.
And honestly, this surprised us less than it should have. In the founder story behind the product, manual prompting and copy-pasting into a CMS was eating 3 to 4 hours a day. That's not rare. That's what manual execution looks like when the system still lives in your head.
LLM Visibility Depends On Repeated Signals, Not Random Good Posts
Question lead: why do some brands show up naturally in AI-generated answers while others with decent content stay invisible?
A lot of it comes down to repeated, credible signals. Clear product definitions. Consistent use cases. Stable terminology. A recognizable point of view. Specific audience language. LLMs tend to reward consistency across scale more than occasional brilliance.
| Dimension | The Strategy-Execution Trade-off | Demand-Gen Content Execution Platform |
|---|---|---|
| Quality control | Relies on downstream review and rewrites | Enforces standards upstream through governance |
| Speed | Increases only by sacrificing consistency | Scales through repeatable, governed workflows |
| Brand voice | Lives in senior leaders' heads | Encoded once and applied across output |
| Product accuracy | Checked manually after drafting | Grounded in approved product truth during creation |
| Multi-writer coordination | Creates handoff overhead and context loss | Gives all contributors the same operating system |
| GEO readiness | Produces scattered signals and narrative drift | Builds consistent, citable brand signals across content |
This is also where outside validation matters. An experienced SEO consultant reviewing output said it "passes the slop test," which is such a useful phrase because everybody in content knows what slop is. Thin ideas. Filler transitions. Generic structure. Synthetic confidence. If your library starts sounding like that at scale, your brand gets easier to ignore.
For grounding on how execution systems beat prompt chains, it's worth reading The Shift Toward Orchestration. And for the broader market pattern, McKinsey's work on gen AI points to the same operational truth: value comes less from raw generation and more from redesigning workflows around it source.
What This Feels Like When You're Living Inside It
Growing teams don't suffer from a lack of effort. They suffer from rework loops that make good people doubt each other.
You Stop Approving Drafts And Start Rewriting Them
A writer sends the draft. PMM adjusts the positioning. Legal changes the product language. Demand gen tones down the CTA. The editor tries to stitch the whole thing back together. It ships late, and nobody is fully sure it still says what the company actually believes.
That's the moment where you realize you're not approving content anymore. You're recreating it.
Review Fatigue Changes How Everyone Behaves
When the same issues keep showing up, trust drops. Writers hedge. PMMs over-explain. Leaders hold onto review longer than they should. Agencies wait for more direction before making a call. Everybody gets a little more cautious, which sounds responsible but usually slows things down and flattens the work.
I've seen teams blame talent here, and sometimes talent is part of it. But often the stronger explanation is that the system trained everyone to wait for correction. Review became the place where clarity happens. That's why the fatigue spreads.
When Nothing Carries Forward, Nothing Compounds
The hardest part is that every asset starts feeling new. New briefing. New context. New correction loop. New argument about what the company means.
And when every asset resets from scratch, nothing compounds. Not SEO. Not product education. Not category framing. Not trust inside the team. Just more work.
For a deeper look at why faster drafting didn't solve this system problem, Google's own guidance around helpful content and people-first quality points in the same direction: consistent, useful, experience-backed output beats scaled generic text over time source.
A Governance Blueprint For Multi-Writer Product Marketing Scale
A governance blueprint for multi-writer scale starts before the draft. That's the whole shift. You stop treating strategy like background reading and start treating it like operating logic.
This approach is designed for teams with multiple contributors, multiple channels, and multiple ways to get off-message. Mid-market SaaS teams. Agency environments. Founder-led teams crossing into scale. Anybody who has enough moving pieces that review alone has stopped working.
- Strategy Encoding: Strategic intent must be translated from slides, docs, and leadership knowledge into explicit operating rules before multi-writer production begins.
- Product Truth Enforcement: Approved claims, positioning boundaries, and use-case accuracy must be embedded in execution so content remains credible as volume grows.
- Audience-Specific Consistency: Each asset should adapt to segment and persona needs without losing the core narrative, voice, or market point of view.
Short version: if the rules don't travel, the brand doesn't either.
Encode Strategy Before You Delegate Production
Bold claim lead. Strategy should be executable before you add contributors. If it isn't, scale will expose the weakness.
Most teams store strategy in non-operational formats. Messaging docs. Notion pages. Launch decks. CEO voice notes. All useful. None of them are enough on their own once five contributors need to produce from the same source of truth.
I like the 3-Layer Transfer Test here. Before you delegate content, ask whether a new writer can answer three things without a meeting: what we believe about the market, what we need this asset to do, and what language we refuse to use. If the answer is no on even one of those, strategy isn't encoded yet.
Critics would say that sounds heavy. Fair. It does require upfront work. But compare that to recurring review repair. If you invest 6 hours once to codify your market POV and save 30 minutes on every future draft, the break-even point arrives fast. Around 12 drafts, you're ahead. After that, you're compounding.
This is also where teams often mistake a style guide for strategy control. A style guide handles surface consistency. Strategy encoding handles meaning. Different layer.
Put Product Truth Inside The Workflow, Not In Slack Messages
Contrast lead. The old way checks product accuracy after drafting. The better way grounds the draft before it exists.
Product marketing scale breaks the moment product truth becomes memory-based. One PMM knows the caveats. One AE knows which use case resonates. One product leader knows the unsupported scenario. One old launch doc has the original language. And now content has to pull from all of them.
That's fragile.
Use the Boundary Rule: if a product claim can trigger a legal, PMM, or founder correction more than twice in a quarter, it belongs in an approved truth layer, not in human memory. Same for feature boundaries. Same for use-case framing. Same for pricing references. Once repeated corrections hit 3+, you formalize.
This is where a lot of AI-assisted product content goes wrong. The system can draft quickly, but if supported claims and unsupported claims are blurry, your review time spikes because accuracy becomes a scavenger hunt. That's why product truth has to sit inside the workflow itself.
And yes, there is a tradeoff. Formalizing product truth can feel slower at first, especially for fast-moving teams. But if your launches keep forcing rewrites because old language bleeds into new assets, you're already paying that cost. You're just paying it late.
Use Audience Rules To Keep Scale From Going Generic
Question lead. Why does content start sounding generic the minute a team gets more productive?
Because audience specificity is usually the first thing to get lost when the machine speeds up. The piece still sounds decent. It still follows a structure. It might even rank. But it no longer speaks like it knows who's reading.
At LevelJump, founder-led content had strong ideas, but structure and search intent were loose. That's one failure mode. The other is the reverse: you get strong structure, but weak audience fit. The piece says all the right broad things and none of the sharp ones.
The fix is to treat audience rules as operating constraints, not optional flavor. I use the 2x2 Framing Check. For every asset, define who it's for, what trigger they're experiencing, what objection they're carrying, and what specific outcome they care about. If you can't fill in all four, the draft will drift generic. Every time.
For agencies, this matters even more. One client's Head of Product Marketing and another client's CMO might both buy software, but they don't read the same way, don't care about the same proof, and don't use the same language. If your writers have to infer that from scratch, quality becomes luck.
This is where you can feel the category shift. A real system doesn't just help create more content. It decides what kind of content should exist, for which audience, with which framing, before production starts. That's a very different operating model.
Some teams are ready to see how that translates into production, not just theory. If that's you, you can request a demo.
How Oleno Makes Governed Execution Real
Oleno puts this category into practice by turning documentation into execution rules. Instead of re-briefing every writer, editor, or agency partner from scratch, the team defines the strategic inputs once and runs content through a system that keeps those inputs attached.
Oleno Connects Strategy, Product Truth, And Audience Context
Oleno uses brand studio, marketing studio, product studio, audience & persona targeting, and use case studio to capture the rules that usually live in docs and people's heads. That means voice, category framing, approved claims, audience context, persona nuance, and use-case detail can shape output before review starts.
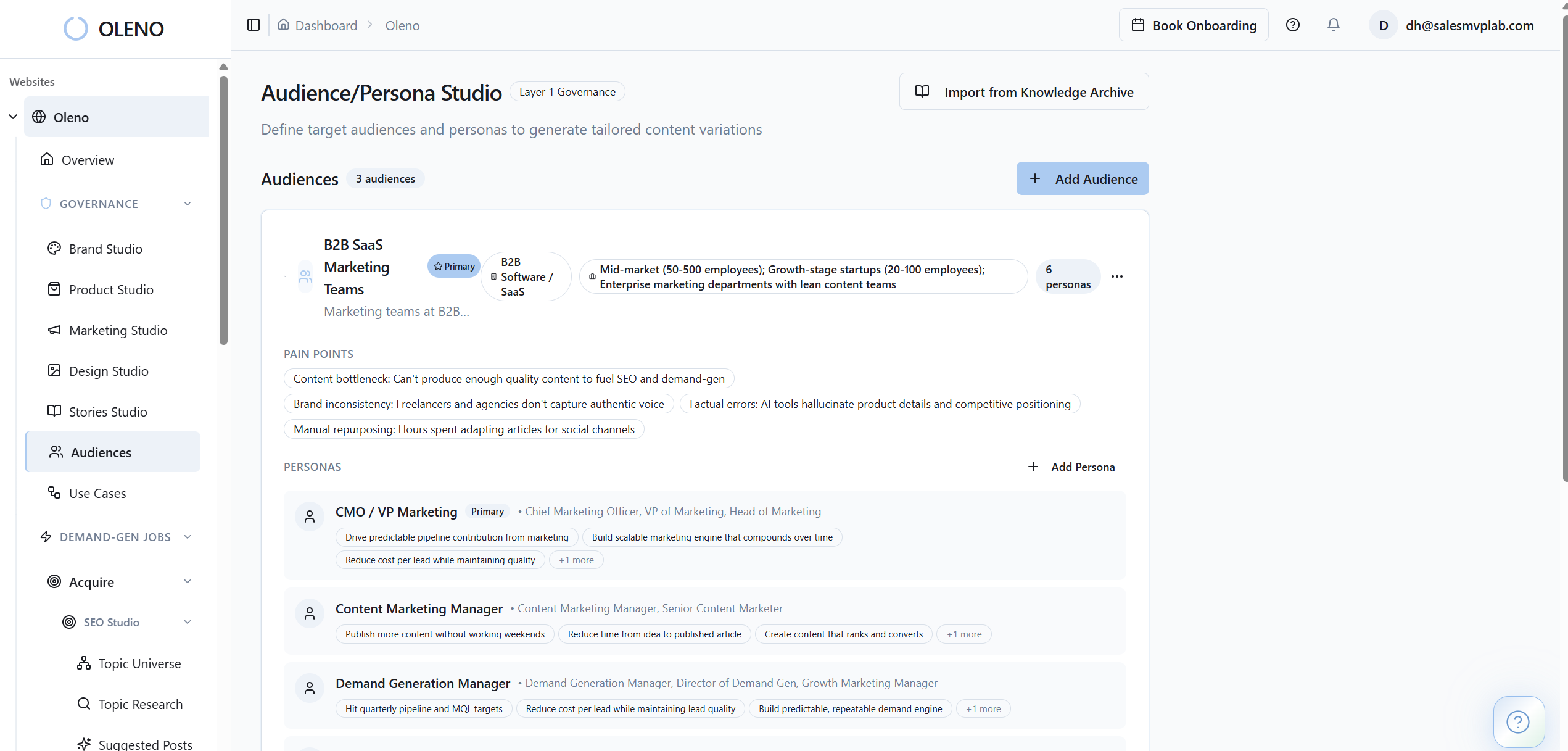
That's the real shift. Marketers stay in control, but they stop carrying the entire system manually. Marketing studio holds the market POV. Product studio keeps product facts and boundaries grounded. Audience & persona targeting and use case studio keep the same topic from getting flattened into one-size-fits-all content.
In practice, that means a product marketing team or agency doesn't need to restate the same strategic context on every brief. They can reuse it. That's not a small thing. That's hours back every month, and fewer rounds of frustrating rework.
Oleno Scales Output Without Handing Strategy To AI
This matters. The system isn't replacing strategic judgment. It's keeping strategic judgment attached to execution.

Oleno's orchestrator moves jobs through a repeatable pipeline. Quality gate checks content before it gets pushed forward. Product marketing studio supports product-led assets like feature deep dives and workflow guides. Category studio, buyer enablement studio, and programmatic seo studio let teams extend the same narrative across different content motions without rebuilding the logic every time.
That matters for multi-writer teams because one of the biggest risks in scale is drift between motions. SEO says one thing. Product marketing says another. Buyer content softens the story again. Then social turns it into generic posting. Governed execution reduces that spread.
If you're evaluating this from an operator lens, the useful question isn't "can it draft?" Plenty of tools draft. The useful question is "can it keep the same story intact across 50 assets and 5 contributors?" That's the harder problem.
Why Teams Say It Feels Like Added Headcount
One customer reaction captured the value pretty well: "This is like adding 3 people to my team." That's not because the system magically invents strategy. It's because the work that used to eat team capacity starts shrinking. Re-briefing shrinks. Rewrite loops shrink. Manual QA shrinks. Publishing overhead shrinks through cms publishing.
And when rework drops, capacity shows up. Not fake capacity. Real room to produce more without immediately increasing headcount.
I'd frame that carefully though. Not every team will feel a full +3 headcount gain in the same way. Smaller teams may feel it as speed and consistency. Agencies may feel it as cleaner client separation and fewer revision rounds. Product marketing teams may feel it as safer throughput on launch and use-case content. The pattern is the same, even if the exact lift varies.
If you want to see how that looks against your current review process, book a demo.
The Teams That Scale Best Stop Treating Review As The Strategy Layer
Multi-writer product marketing doesn't break because writers are bad, or because AI is bad, or because teams want too much output. It breaks because strategy keeps falling out of the workflow, and humans have to put it back in by hand.
That's the Strategy-Execution Trade-off. And it's costly because it feels normal.
The better path is pretty clear. Encode strategy before delegation. Put product truth inside the workflow. Keep audience rules attached to every asset. Do that, and scale stops feeling like a quality compromise. It starts feeling like a system.
That's really what this category is pointing at. Not better drafting in isolation. Better execution across time.
About Daniel Hebert
I'm the founder of Oleno, SalesMVP Lab, and yourLumira. Been working in B2B SaaS in both sales and marketing leadership for 13+ years. I specialize in building revenue engines from the ground up. Over the years, I've codified writing frameworks, which are now powering Oleno.
Frequently Asked Questions