Automated QA Gate: 10 Pre-Publish Checks to Prevent Content Failure

Most teams swear they have a “solid QA process.” Until Friday at 4:55 p.m. when the launch post ships, rich results vanish, and someone is stuck debugging JSON-LD in a panic. I’ve been there. You only need two or three of those weeks in a row to realize the problem isn’t effort. It’s structure.
Manual reviews are heroic. They’re also inconsistent. People get tired, busy, or pulled into meetings. Structure slips. Schema slips. Alt text slips. And once it’s live, you’re fixing defects in production instead of preventing them. The fix isn’t more proofreading. It’s an automated pre-publish gate that enforces rules the same way, every time.
Key Takeaways:
- Manual QA fails because important checks are variable; convert them into deterministic tests that block publish on failure
- A pre-publish gate should score, fail-fast on blockers, auto-remediate what’s safe, and queue judgment calls for humans
- Quantify costs: every post-publish fix is rework that compounds into lost hours and credibility hits
- Gating priorities: structure and schema first, content differentiation and voice next, reliability and duplicate detection always
- Keep humans on narrative and differentiation; let the system police structure, links, images, and schema
- The minimum bar should be explicit (e.g., 85 overall, with hard blockers)
- You can ship a basic gate in a week with scripts, CI, and CMS webhooks
Why Manual QA Lets Bad Content Slip Through
Manual QA misses non-negotiables because people prioritize prose over structure when time gets tight. The result is predictable: inconsistent snippet openers, missing alt text, and schema regressions. A gate converts “shoulds” into pass/fail checks and keeps human focus on the narrative, not hunting defects.

The checks that never get done consistently
Here’s the thing. You won’t catch structure violations at 4:45 p.m. before a release. People read for flow, not hierarchy. That’s why missing snippet-ready openers, thin H2 answers, and broken heading order sneak through. Same with image hygiene and internal links. They look “fine” to a human skimming a nice paragraph.
What you can do is make these mechanical checks deterministic. Validate that each H2 opens with three sentences, 40–60 words. Force 5–8 verified internal links pulled from your sitemap. Require hero + 2–3 inline images with alt text and SEO-friendly filenames. If it’s reviewable, it’s testable. And if it’s testable, it should be gated.
Why a gate should be automated, not optional
Optional means “skipped when busy.” A gate is binary: run, score, pass or block. A gate is binary: run, score, pass or block. This doesn’t replace editors; it protects them. When a policy is code, humans spend time on narrative judgment, what the story should be, not on whether an image filename has a hyphen.
We learned this the hard way on a high-volume operation I ran years ago. At scale, inconsistency is your enemy. The teams that win write with judgment and ship with rules. Set a clear threshold (say, 85) with critical blockers. Add automatic remediation loops for safe fixes, alt text generation, tone normalization, and reserve exceptions for people.
[EARLY CTA] Want to see what a working gate feels like without rebuilding your stack? Try a mini-production test. Try Generating 3 Free Test Articles Now.
What a Pre-Publish Gate Must Actually Check
A pre-publish gate should translate editorial standards into numeric signals and pass/fail thresholds. Score structure, tone, and differentiation; block on schema, link count, and duplicates. Run cheap checks first and save expensive checks for later to fail fast and reduce rework.

How do you convert qualitative rules into scores?
You turn policy into math. Style rules become banned term counts and tone scores. Structure turns into heading validation, paragraph length bands, and snippet-opener checks. Differentiation becomes an Information Gain Score threshold. Accuracy ties to knowledge base grounding and retrieval density.
The rubric doesn’t need to be perfect on day one. It needs to be explicit. For example: 85 minimum overall, pass only if every H2 opener is 40–60 words, require 5–8 internal links, 1 KB-backed fact per section, and tone score ≥ 80. Start simple. Add sophistication when drift appears. If you’re scaling automation, this is your foundation, scorecards, not vibes. For context on automation patterns at scale, Smartling’s overview on automated content generation provides useful baseline language principles you can adapt into checks.
Ordering checks for fail-fast pipelines
Treat QA like a production pipeline. Run cheap, deterministic checks first: structure, headings, image presence, alt text, link counts, schema presence. If those fail, stop. Only proceed to expensive checks, deeper KB retrieval, information gain, and tone normalization, once basics pass.
Use severity levels. Some failures auto-fix (missing alt text). Some block (schema invalid). Some queue for human review (low information gain). This saves cycles, reduces cloud spend, and keeps throughput stable. If you’re new to gating, the “publish only when green” discipline from CI/CD applies; see the “fail-fast” guidance in UiPath’s publishing best practices for a parallel mindset.
The Hidden Costs of Post-Draft Fixes
Post-draft fixes drain hours and dilute credibility. Every rollback, republish, and “quick image patch” is time you could have spent improving the story. Multiply small defects by volume and you’ll find an invisible tax on your team’s week.
Engineering hours lost to re-publishing and hotfixes
Let’s pretend you publish 30 posts a month. If 30% need schema or image fixes post-publish, at 30 minutes per fix, that’s 4.5 hours gone. Add one rollback incident at two hours and you’re near a full day lost. Do that for a quarter and you’ve burned 3–4 days of unnecessary rework.
I’ve watched this play out on small SaaS teams. When speed is the KPI, you push. Then you pay the tax later, dev time for hotfixes, content re-approvals, stakeholders asking “what happened?” A gate removes the roulette. Orbit Media’s evergreen “web content checklist” covers many of these hygiene items; your system should enforce them, not hope for them.
Reliability signals your CMS should never ignore
There are a few reds that should always block publish: schema missing or invalid; internal links fewer than five; duplicate detection above your threshold; broken or off-brand images; knowledge base anchors missing. Your CMS should log the reason, keep the artifact, and mark as retriable.
No silent failures. No “we think it shipped.” When reliability is explicit, your team stops guessing and starts improving. The difference is night and day in weekly ops reviews. And yes, you’ll sleep better when Friday deploys don’t carry hidden risk. For broader quality processes, Lumina Datamatics’ take on publishing quality management maps neatly to pre-publish governance.
When Quality Fails at the Worst Moment
Quality usually fails at the worst possible time, launch day, board update week, or when a partner is watching. The patterns are repeatable: schema breaks, tone reads synthetic, or visuals don’t match the brand.
The Friday publish that broke your schema
You ship a big launch post. No schema deployed. Rich results evaporate. The fix lands Monday, but the window is gone. A gate prevents this by generating and validating JSON-LD before anything leaves draft. If validation fails, publishing does not happen. Period.
That’s not harsh. It’s respectful of your week. Schema presence and validation are cheap to check and catastrophic to miss. For a deeper primer on this failure mode, see the playbook on reducing rich result failures with JSON-LD validation.
The broken image on a launch day article
You’ve seen it: hero fails to load, alt text is empty, filenames look like “image (1).png.” Inline visuals? Off-brand and distracting. Editors scramble, designers get pinged, and a small defect steals attention from the message.
A gate ends the drama. Verify image presence, size, alt text, and filenames; check visual style rules so your content “looks like you.” Auto-generate alt text when missing, then re-test. Humans still pick the right story. Machines make sure the visuals won’t embarrass you.
[ MID CTA ] Want fewer “we need to unpublish” moments? It’s doable. Try Using an Autonomous Content Engine for Always-On Publishing.
Build a Production-Ready QA Gate in Your Pipeline
A production-ready gate enforces structure, voice, KB grounding, and reliability with clear thresholds. Start with policy as code, run checks in a fail-fast order, and keep remediation loops separate from the publish path to protect throughput.
Checks 1–2: Structure compliance and snippet-opener validation
Structure is cheap to verify and expensive to ignore. Validate H1–H3 hierarchy, list hygiene, paragraph length, and that every H2 opens with a three-sentence, 40–60 word direct answer. If not, fail. Don’t ship without snippet-ready openers; they’re your clarity signal for both humans and machines.
Make it explicit in code: if headings_invalid or opener_len outside 40–60 words or sentences != 3, then block. Provide an auto-rewrite suggestion for openers, re-test, and only then proceed. This is where machines shine. They deliver consistent, tireless enforcement of boring but vital rules.
Check 3: Information gain threshold
Repetition wastes slots. Require an Information Gain Score before publish (e.g., 65–70 minimum). Compare against top-ranking coverage and your own sitemap to ensure you’re adding something new, not echoing what’s already out there.
When a draft misses the bar, queue it for human review with targeted prompts: add an example, introduce a contrarian angle, include data, or integrate a unique process. Then re-score. This keeps your cadence high without publishing content that adds no net-new value.
Checks 4–6: KB-grounded citations, tone normalization, and AI-scent filtering
Accuracy lives in your knowledge base. Validate that factual claims tie back to KB anchors; require at least one KB-backed fact per section. If kb_anchors_per_section < 1, fail. This reduces drift and keeps claims consistent with your product and positioning.
Then enforce brand voice: banned terms, rhythm targets, and tone score. If banned_term_count > 0, fail; if tone score < 80, remediate and re-test. Finally, filter AI-scent, generic transitions, repeated structures, filler phrases. Keep this list curated to your brand and update as patterns drift. Robots handle the structure; people keep the story sharp.
Checks 7–9: Deterministic internal links, images, and schema
Links should be deterministic: 5–8 internal links from verified sitemap URLs, exact-match anchors to page titles, and placement at natural sentence boundaries. If count outside range or anchors don’t match, fail. Never fabricate URLs.
Images and schema are non-negotiable. Require hero + 2–3 inline visuals with correct aspect ratios, non-empty alt text, and SEO-friendly filenames. Generate and validate JSON-LD (Article, FAQ, BreadcrumbList as needed). If schema missing or invalid, fail. Store validated payloads so publishing is idempotent and reversible. Interjection. You’ll feel the stress drop the first week this is live.
Check 10: Duplicate and near-duplicate detection
Compare content against your existing catalog using embeddings or shingles. If similarity_to_existing > 0.85, block and suggest canonicalization or a rewrite. Also block if the target slug already exists to prevent duplicate publishing.
This single check saves reputational risk and avoids cannibalizing your own coverage. Duplicates happen by accident in busy teams. The gate makes it impossible to miss.
Lightweight tooling options you can ship this week
You don’t need a platform to start. Scripts plus CI get you 60% of the way. Add CMS webhooks to gate at draft. Use serverless functions for async remediation, alt text generation, tone rewrites, and snippet-opener suggestions. Parse HTML or markdown, run validators, update status, and block publish if red.
Make it reversible and idempotent. Publish should never be a one-way trip. If that sounds familiar, it’s because mature content operations borrow from software delivery. If you want more context on operationalizing content automation, this overview of content production best practices maps nicely to a gating mindset.
How Oleno Enforces Pre-Publish Quality Without Manual Edits
Oleno enforces pre-publish quality by turning policy into code, running 80+ checks, and only shipping articles that clear explicit thresholds. It handles links, visuals, schema, and tone automatically, then publishes to your CMS with duplicate prevention and reliable retries.
Oleno’s deterministic internal linking and schema steps guarantee structural hygiene. It injects 5–8 internal links using only verified sitemap URLs with exact-match anchors at natural sentence boundaries. Then it generates and validates JSON-LD for Article, FAQ, and BreadcrumbList as applicable, attaches it to the payload, and locks the artifact. Fewer crawl leaks. More reliable rich results. No manual templates.
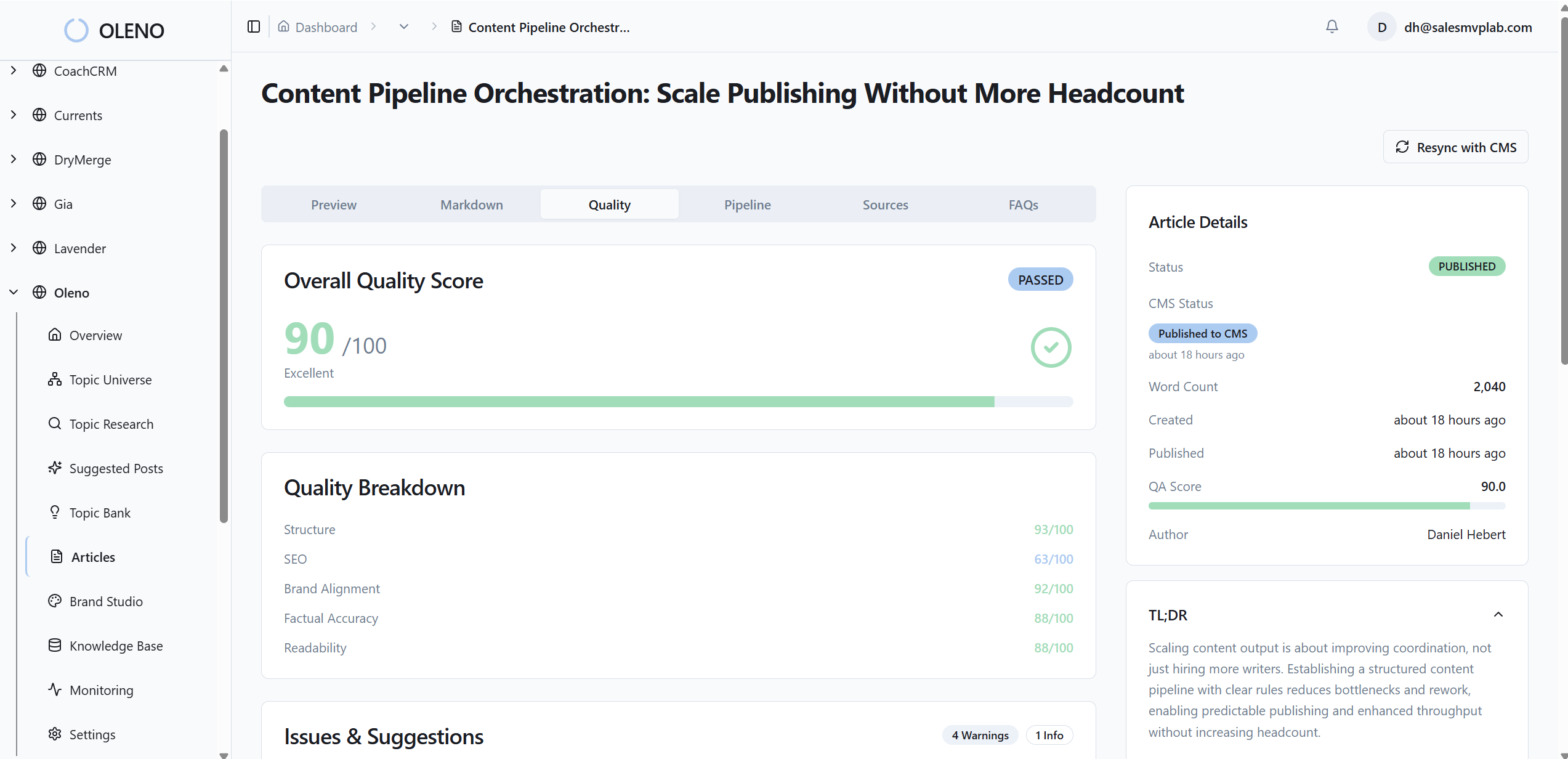
Every draft runs through Oleno’s QA gate with more than 80 criteria across structure, information gain, brand alignment, snippet readiness, visuals, and more. Low-scoring areas trigger refinement loops. AI-scented phrasing is removed, tone is normalized, and the article re-tests until it clears a defined minimum threshold, typically 85. This is where teams save the most time: editorial judgment moves to story and differentiation while routine fixes happen automatically.

Visuals are handled by Visual Studio. Oleno generates a hero and 2–3 inline images with your colors, marks, and style references. It semantically matches product screenshots to relevant sections and writes SEO-friendly alt text and filenames. Solution sections look like you, not stock. The credibility gap that often appears at launch shrinks, consistently.
Finally, Oleno publishes the locked, validated article via connectors like WordPress, Webflow, or HubSpot. It maps fields, supports draft or live modes, prevents duplicate posts by design, and triggers notifications on failure so you can retry without creating mess. Text, visuals, links, and schema ship together, predictably. The result is the opposite of “we’ll fix it after it goes live.” It’s “we don’t ship until it’s right.”
Ready to offload the policing and keep the storytelling? Try Oleno for Free. Or, if you want to test it with your content before committing, Try Generating 3 Free Test Articles Now and see the QA gate in action.
Conclusion
You don’t need more editors or longer checklists. You need a gate. Put policy into code. Score it. Block on red. Auto-remediate the safe stuff and reserve people for judgment calls. That’s how you prevent Friday surprises, cut rework, and keep your best brains on story, not structure.
If you adopt one idea from this: make non-negotiables non-optional. The minute your CMS refuses to ship bad structure, broken schema, thin differentiation, or missing alt text, everything else gets easier. The content still needs your taste and insight. The system just makes sure it ships right, every time.
About Daniel Hebert
I'm the founder of Oleno, SalesMVP Lab, and yourLumira. Been working in B2B SaaS in both sales and marketing leadership for 13+ years. I specialize in building revenue engines from the ground up. Over the years, I've codified writing frameworks, which are now powering Oleno.
Frequently Asked Questions