Content Saturation Audit: 7-Step Cooldown Playbook to Stop Over-Publishing

Most teams think the cure for flat traffic is hitting publish more often. I thought the same years ago when I ran Steamfeed. We grew fast, 80 regular contributors, 300 guests, a tidal wave of pages. Volume plus quality gave us reach. Then I joined small SaaS teams and saw the flipside. A few strong signals buried under piles of similar articles. Rankings level off. Sales asks for “the one page to send” and you have five.
I have the scars from both sides. At PostBeyond, when it was just me, I could ship 3–4 solid posts a week because the framework was tight. As headcount grew, content got slower and thinner. At LevelJump, we moved faster with transcripts, but structure suffered and search intent slipped. At Proposify, the content was loved, but too far from the product. We ranked. We did not convert. That tension is what this playbook fixes.
Key Takeaways:
- Stop measuring output volume, start measuring cluster health and information gain
- Build a normalized content inventory to expose overlap before it ships
- Score saturation at the cluster level and attach cooldowns to topics, not URLs
- Use information gain checks to route drafts to refresh, merge, or block paths
- Enforce cooldowns in your CMS with publish blockers, webhooks, and an exception ledger
- Operationalize approvals, then measure blocked publishes and reclaimed hours
- When ready, let an autonomous engine enforce rules so coverage compounds
Why Publishing More Dilutes Authority (And How Saturation Hides)
Publishing more dilutes authority when new articles repeat what you already said, creating noise instead of signal. The cost shows up as duplicate angles, split link equity, and confused readers who cannot find your canonical answer. You feel it when five “how-to” pages fight your own product page.

The hidden cost of over-publishing
Let’s pretend you ship 12 overlapping articles a month at four hours each. That is 48 hours of work for tiny additive value. Do that for three months and you just burned six weeks of capacity that could have gone to refreshes or one definitive guide. The deeper cost is confusion. Readers bounce between near-identical takes, and assistants trained on the open web pick up mixed signals. Saturation is a tax on trust.
I have lived this. We had five variants of “sales onboarding plan” at LevelJump, created months apart by different owners. None were wrong. All were similar. Internal links drifted, updates lagged, and the “right” answer depended on who you asked. That is how clusters get noisy. It rarely says duplicate on the tin. It whispers same-same in the subheads.
If you want a wider industry lens, the long tail of content is crowded. A landscape view from Marketing Insider Group on content saturation shows why “more” often underperforms once your category matures. The fix is system-level, not copy edits. Start with autonomous content operations thinking so you coordinate strategy, structure, and shipping.
Reframe the metric
Output count is a vanity metric. Cluster health is not. Track coverage, saturation, and information gain at the pillar level. If a draft cannot add new facts, examples, or decisions, it is probably stealing oxygen from a refresh, merge, or consolidation. The target is authority over time, not wins per week.
Build Your Inventory: Export And Normalize The Data
You cannot manage saturation you cannot see. Build a source of truth that lists every live page and what is in the pipeline. Start with CMS and sitemap exports, then normalize fields so joins and comparisons are clean. The goal is a single table that supports fast overlap checks and clear decisions.

What data should you export?
Export from CMS, your sitemap, and any structured knowledge base you maintain. Include url, slug, title, h1, canonical, content type, status, publish date, last modified, owner, tags, word count, cms_id, canonical_group, redirect_target, and a free-text pillar guess. If you have it, add “last refresh” as a separate field. Pull drafts and scheduled posts too. Saturation is caused by what is planned as much as what is live, so add “pipeline_status,” “intended_topic,” and “target_cluster” to catch redundancy before it hits publish.
Create a light “section map” column. Store the first 5–10 words of each H2/H3 in a single string. Later, you can run simple phrase overlap checks without heavy models. The field list may feel like overhead. It is the opposite. Clean data is what makes enforcement cheap. For structure fundamentals, the Content analysis methodology from UT Austin is a solid reference point.
You can prevent a lot of mess by thinking ahead about delivery. If you plan to automate publishing, see how deterministic CMS publishing avoids duplicate posts and brittle field mapping.
How do you normalize and dedupe?
Normalize titles and slugs. Lowercase, trim whitespace, remove trailing slashes, collapse UTM variants. Create “url_norm” and “title_norm” to anchor joins. Unify content types by mapping free-form CMS types into a consistent set you use for scoring later: article, guide, comparison, feature, doc, landing. Store both “type_raw” and “type_norm” so you can trace source values.
Collapse canonical groups. If your CMS uses canonical fields, group by “canonical_group.” If not, build temporary groups by matching url_norm patterns, for example /topic/ versus /topic/?page=2. This prevents scoring noise and helps you decide what merges versus refreshes. It also sets you up to align with governance-first ops later, which is why weaving this inventory into governance first ops pays off.
Map Clusters And Score Saturation Across Your Pillars
Clustering makes saturation visible at a glance. Group pages by pillar and subtopic using paths, tags, and section maps. Then score each cluster with a simple model that incorporates live posts, scheduled posts, and near-duplicates. Your output is a clear level for each cluster and a list of drafts to pause.

How do you group pages into pillars?
Start with path and tag based clustering. The first path segment or a consistent tag set can assign a “cluster_id” quickly. Refine with section maps. If two or three H2s overlap across pages, roll them together. Aim for decision-ready clusters, not perfect taxonomy. Add a “topic universe” view that lists intended topics per cluster, including approved ideas, drafts, and live pages. Seeing planned plus live together surfaces saturation you will miss if you look only at what is published.
Validate edge cases. Some pages carry cross cutting themes. Give them a primary_cluster and a secondary_cluster. Only the primary should count toward saturation unless you intentionally design a shared cluster. If you need a refresher on why this matters structurally, read the content operations breakdown. And if you are shifting from output speed to governed coverage, this is exactly where autonomous systems thinking helps.
Compute saturation levels with clear thresholds
Define a saturation score that fits your cadence. A practical formula looks like this, kept simple on purpose:
- Saturation score = live_count_90d + scheduled_count_30d + near_duplicate_count − refresh_count_90d
- Levels: 0–1 underserved, 2–3 healthy, 4–5 well covered, 6+ saturated
Add “topic recency” friction. If any page in the cluster has a publish or refresh date in the last 90 days on the same subtopic, add two points. This discourages micro rehashes. Then output a “cooldown_ready” flag when a cluster crosses well covered and a draft targets the same subtopic. That flag will power your CMS blockers and exception routes. If you want a defensible scoring mindset, a methods paper like this categorical scoring guidance from SAGE Journals is useful.
Detect Redundancy And Run Information-Gain Checks
Information gain is your north star for whether to ship, refresh, merge, or block. You are asking one question: what is materially new here. Define “new,” test for overlap using section maps, and set a passing threshold so volume does not sneak back through exceptions.
What is “information gain” and how do you test it?
Define new as new data, decisions, examples, visuals, or counter positions. Quick checks work well. Look for unique entities not present in cluster peers, an original framework or decision tree, and a fresh scenario sourced from your product or knowledge base. If none exist, the draft is probably low gain. Run pragmatic overlap checks by comparing draft H2 and H3 phrases to section maps in the cluster. If at least half of the phrases overlap and no new data points are declared, flag it as a low_gain_candidate.
Set a passing threshold. Require an information_gain_score of 60 out of 100 to move forward. If a draft falls short, route it to refresh or merge recommendations. You will make exceptions occasionally, and that is fine when explicit. If you like formal criteria, this methodological rigor reference on categorical assessment pairs well with your internal bar. For a practical workflow writers can apply, share this explainer on information gain scoring.
When should you merge, refresh, or block?
Merge when two pages answer the same question for the same audience with similar structure. Keep the stronger URL, redirect the weaker, and carry forward any unique sections. Refresh when the existing page remains canonical but needs updated facts, visuals, or a better decision aid. Block when the draft adds nothing material. If it is a near copy with lighter examples, stop it, then convert the energy to a refresh with a delta plan that lists three new facts, one new decision table, and a product screenshot you will add.
Document exceptions. Product launches, security updates, or critical policy changes may bypass the gate. Still require a short note with who approved it and why. That is how you keep teams honest without slowing urgent work. If you need a formal policy backbone, route exceptions through your content governance playbook.
Curious how this looks in a full system? Try generating 3 free test articles now.
Design Cooldowns And Operationalize Enforcement In Your CMS
Cooldowns prevent accidental re coverage. They also create breathing room for meaningful refreshes. Set 30, 90, and 180 day rules based on cluster saturation and topic criticality. Then put those rules in code with publish blockers, webhooks, and a clean exception process you can audit.
How do you set 30/90/180-day rules?
Start with 90 days for re covering the same topic and subtopic within a cluster. Use 30 days for news or investor relations updates when speed matters. Use 180 days for saturated clusters where noise is your enemy. Attach the rule to the topic plus subtopic, not just a URL, so rehashed angles do not sneak through on new slugs. Add exception classes. Fast path for security disclosures and compliance changes. Slow path for seasonal refreshes and community announcements. Each class needs an approver and a required “what is new” note.
Tie rules to signals. If saturation is well covered or higher, double the cooldown. If a refresh clears an information_gain_score of 75 and the page is not net new, allow a bypass with editor approval. This keeps you fast without inviting redundancy. If speed only approaches have burned you before, this walkthrough on AI writing limits explains why cooldowns matter.
How do you enforce cooldowns with publish blockers and webhooks?
Add fields to your CMS: cluster_id, subtopic_key, last_coverage_date, cooldown_until, information_gain_score, exception_class, exception_note, approver. Block publish if today is before cooldown_until and no approved exception exists. Drafts stay draft with a clear reason. Use webhooks on save or schedule to call middleware that recalculates cluster saturation and cooldowns. If blocked, return a friendly error with the next eligible date and the exception path. Enforce idempotency on publish endpoints using cms_id plus subtopic_key. If a matching post exists within the window, fail gracefully and suggest a refresh instead. The benefits are not just operational, they tie to reproducibility principles. See how protocol enforcement reduces error in this NLM paper on reproducibility and protocol compliance.
Interjection. If you only implement one thing from this playbook, make it the publish blocker.
Who approves exceptions and how are they audited?
Define approvers by exception class. Product and legal for security and compliance. Product marketing for launches. A managing editor for seasonal content. No single person should approve all. Rotate approvers to reduce bias toward “just ship it.” Keep an exception ledger that stores exception_class, reason, approver, and the “what is new” delta statement. Review it monthly. If more than 20 percent of exceptions cite “timely angle,” your policy is too loose or your cluster is under specified. Measure operational impact. Track blocked publishes, converted refreshes, average information_gain_score, and QA pass rate at first attempt. Let’s pretend you block ten low gain drafts this month and convert six to refreshes. That is roughly 24 hours reclaimed, plus a cleaner cluster signal. For thresholds that backstop exceptions, study QA gate design patterns.
Ready to eliminate frustrating rework from near duplicates? Try using an autonomous content engine for always-on publishing.
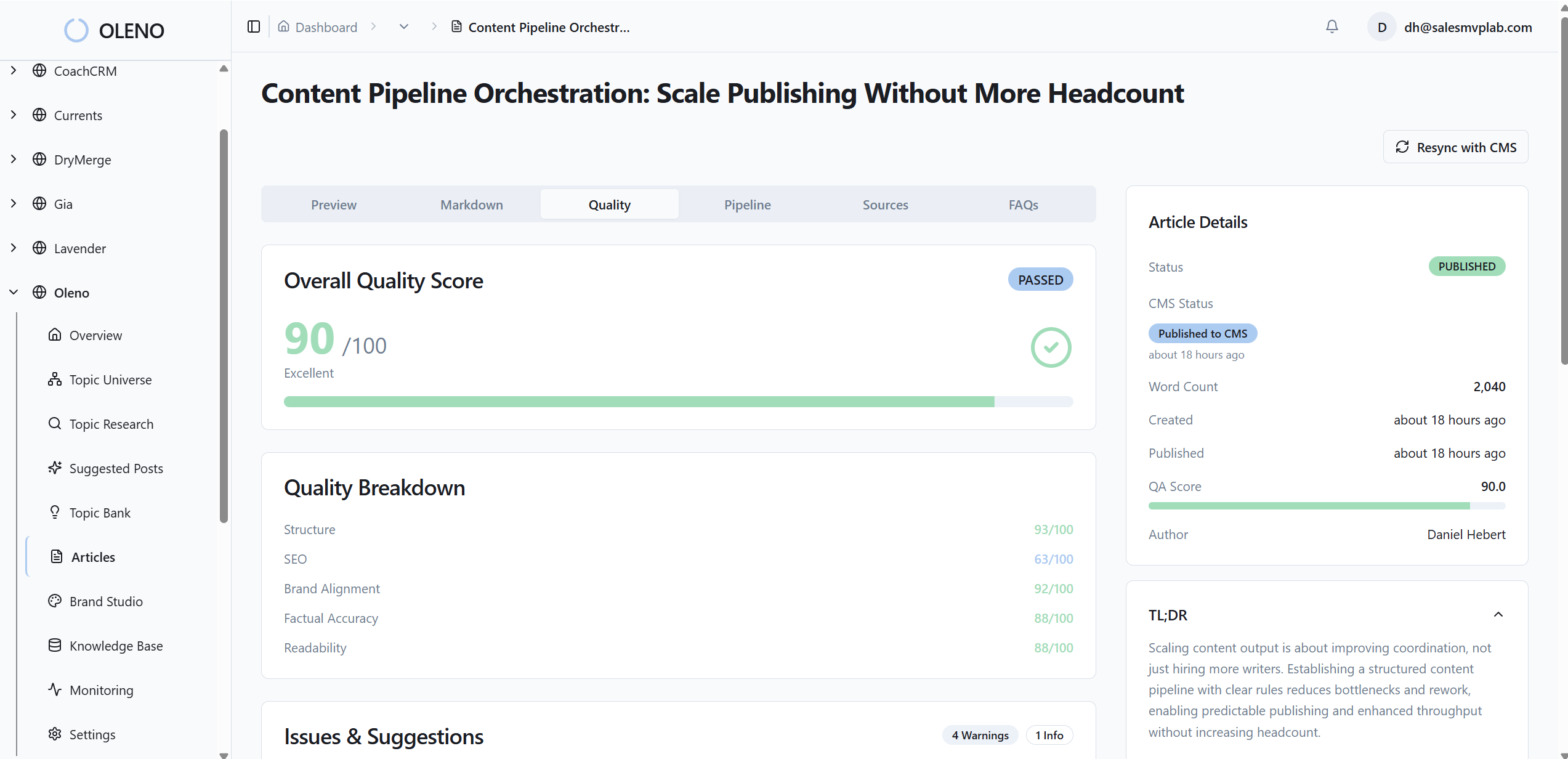
How Oleno Automates Cooldowns, Saturation Control, And Refreshes
When the playbook works, you can hand it to a system. That is the point. A governed pipeline runs daily, keeps your topic universe balanced, enforces cooldowns, and prevents accidental duplication. You do not get dashboards. You get articles that compound authority by design.
What does Oleno handle out of the box?
Remember the six weeks of capacity you burned on low gain overlap. Oleno closes that gap with three core capabilities. First, Topic Universe maps your pillars, tracks coverage, calculates saturation, and enforces a 90 day cooldown before re covering the same topic. Brief generation includes competitive research and computes an information gain score, so low differentiation drafts are flagged early and redirected to refreshes or merges. Second, quality gates keep standards steady. Every H2 starts with a snippet ready paragraph, brand voice constraints are applied, and 80 plus QA checks validate structure, clarity, and referenceability before anything ships. Third, delivery is handled. Articles publish directly to WordPress, Webflow, or HubSpot with fields mapped automatically.

Discover how coordination beats raw draft speed in the content orchestration shift.
Deterministic controls that prevent duplication
Oleno uses deterministic systems where accuracy matters. Internal links are injected algorithmically using only verified URLs from your sitemap, with anchor text matching page titles. Schema is generated programmatically and attached as metadata. Connectors convert markdown to CMS ready HTML, embed visuals and metadata correctly, and prevent duplicate publishing by design using idempotency checks. Visual Studio generates brand consistent hero and inline images, and matches product screenshots to relevant sections using semantic similarity, so the most product centric sections get the right visuals.
This combination reduces noisy churn in saturated clusters and raises quoteability across Google and assistants. If you are working both search and LLM surfaces, read how clean clusters improve mentions in dual discovery surfaces.
When should you consider the platform?
If your week includes debates about duplicates, retroactive merges, and last minute edits to fix structure, it is time to offload enforcement. Oleno is built for teams that want content to compound. You keep strategy guardrails. Oleno runs the loop end to end, topic to publish. Teams managing multiple sites or brands get consistency across visuals, links, schema, and cooldowns as rules, not reminders. When the motions feel stable in your docs, let Oleno turn those policies into execution, every day.
Want to see this run with your topics, not a demo set. Try Oleno for free.
Conclusion
Publishing more is not the enemy. Publishing more of the same is. When you inventory your content, normalize fields, cluster by pillars, and score saturation, the bloat becomes obvious. When you define information gain and route drafts to refresh, merge, or block, your signal sharpens. When you put cooldowns in code and add a publish blocker, you defend that signal on busy days.
You do not need a big team to do this. You need a system that enforces what you already know is right. Start with the audit and cooldown playbook. Then, when you are ready to reclaim those six weeks of drift, let a governed engine run the loop while you focus on what to write next.
About Daniel Hebert
I'm the founder of Oleno, SalesMVP Lab, and yourLumira. Been working in B2B SaaS in both sales and marketing leadership for 13+ years. I specialize in building revenue engines from the ground up. Over the years, I've codified writing frameworks, which are now powering Oleno.
Frequently Asked Questions