How to Build Content as Infrastructure: An 8-Step Playbook

Back when I ran Steamfeed, we published a ton. 80 monthly contributors, 300 guests, and spikes at 500, 1,000, 2,500 pages. It worked because we had breadth and depth. But when I moved into lean SaaS teams, the reality hit: speed without structure just creates cleanup. You publish more and feel productive. Then spend weeks fixing what shouldn’t have shipped.
Here’s the punchline. Content behaves like infrastructure. It compounds if you wire it with rules, memory, and continuous operations. Otherwise, it decays. You get duplication, off-brand tone, broken visuals, and publishing friction. Not fun. Avoidable, though.
Key Takeaways:
- Publishing faster without coverage rules creates duplication and drift
- Treat content as a system with persistent memory and deterministic gates
- Quantify information gain before drafting to prevent me-too pieces
- Enforce snippet-ready structure to increase citation eligibility
- Automate visuals, schema, and internal links with code, not vibes
- Run an always-on pipeline so each article improves the next
- Small teams can ship big with rules that machines enforce
Why Publishing More Often Creates Diminishing Returns
Publishing more often usually dilutes authority because teams repeat angles, drift off-brand, and split internal links. The fix isn’t “more posts”; it’s coverage discipline and cooldowns across clusters. For example, two near-duplicates in the same topic can cannibalize each other for months.

The misleading dopamine of output volume
I’ve felt the rush of shipping three posts a week. It looks like progress on a calendar. It rarely translates to authority. When I was the only marketer at PostBeyond, I could produce fast because the voice lived in my head. As the team grew, quality dipped and rework climbed. Output hid the real problem: fragmentation.
What’s happening under the hood is simple. Without a Topic Universe and saturation model, teams keep circling the same ideas. Internal links get scattered. Sections don’t follow a snippet-ready pattern, so they’re hard to cite. You end up spending time fixing tone, expanding thin sections, and closing gaps you could have prevented upstream.
The alternative isn’t slower work. It’s coordinated work. Map clusters. Set cooldowns. Define what “new” means before drafting. And make visuals, schema, and links deterministic so you’re not patching the same things every Friday. If you want a strategic deep dive on this “content as infrastructure” idea, the framing in Content as Infrastructure lands well.
Treat Content Like Infrastructure, Not Projects
Treating content like infrastructure means installing persistent memory, rules, and a single pipeline that runs daily. You enforce differentiation before drafting and wire visuals, schema, and links by rule. The outcome is predictable: fewer surprises, fewer fixes, more compounding.

What changes when you install a system, not a sprint plan
Projects end. Infrastructure runs. When content becomes infrastructure, you stop debating taste and start encoding standards. Topic selection pulls from coverage gaps, not Slack ideas. Differentiation is scored before anyone writes. And the publishing “last mile” is code, not a Tuesday afternoon scramble.
The biggest relief? Governance moves to the front. Voice constraints, banned terms, and KB-grounded claims are checked at the gate, not by a heroic editor post hoc. Structure becomes predictable, every H2 opens with a direct answer, and visuals show up on-brand by default. You get consistent articles people reference, not just read. If you want a companion perspective on why infrastructure belongs in content strategy, this piece from Contentful is useful: Why infrastructure is part of content strategy.
How do you make content compound instead of decay?
You compound by installing feedback loops. Map your Topic Universe, track saturation, and enforce cooldowns so each publish improves your authority map. Then, score information gain so drafts add something new. Finally, make QA pass/fail with remediation loops that fix known issues automatically. No “shoulds.” Just rules.
At LevelJump, we were three people. Founder-led content kept us moving, but without structure we duplicated ideas and missed key schema. Once we codified rules, topic coverage, voice constraints, and format, we stopped firefighting and started stacking wins. The system iteratively improved because we designed feedback loops.
A good system feels a bit boring. That’s a feature. It lowers variance and lets your best ideas carry the weight. When the process is predictable, your narrative can be opinionated, specific, and helpful. The way it should be.
The Silent Costs Of Ad-Hoc Production
Ad-hoc production looks cheap until you count rework, missed cycles, and authority split. The measurable cost is time; the hidden cost is momentum. Teams pay both, quietly, every quarter.
Where the budget actually goes when structure is missing
Let’s pretend you publish 20 posts this quarter. Ten need voice rewrites. Five duplicate coverage. Eight ship without valid schema or correct internal links. At three hours of fixes per post, you’re staring at roughly 69 hours of frustrating rework. That’s two work-weeks lost to cleanup nobody budgeted for.
The opportunity cost compounds. Those hours delay the next brief, slow design requests, and push publishing into end-of-month rushes where mistakes multiply. Worse, the mental tax builds. People get cautious, then slow, then inconsistent. A deterministic pipeline, one that treats internal links and schema like code, cancels those failure modes. If you like formal approaches to operational discipline, the mindset in the Infrastructure Playbook translates well to content systems.
Why duplication and drift kill cluster authority
Duplication splits signals. You siphon internal links and relevance from a strong page to a near-twin, and both underperform. Drift does similar damage. One off-brand piece in a cluster makes the whole pillar look fuzzy. The algorithm doesn’t punish you. It just picks someone clearer.
This is where a saturation model pays for itself. Label clusters Underserved, Healthy, Well-Covered, or Saturated. Enforce a 90-day cooldown before re-covering the same topic. And require a minimum information gain score to re-enter a cluster. Those rules keep you from stepping on your own toes.
What It Feels Like When Quality Slips
Quality slips don’t show up as one big fire. They arrive as small, persistent annoyances, voice off, visuals generic, links wrong. Over time, those annoyances create real drag. People notice.
The off-brand article that keeps showing up in sales calls
You know the one. A clever idea that doesn’t sound like you, with a mismatched screenshot and two broken internal links. Sales apologizes for it on calls. Product shrugs. Marketing adds “Fix post X” to the backlog again. Nothing here is catastrophic. It’s just waste.
I’ve been on the receiving end of this at Proposify. Content that ranked had nothing to do with sending and signing proposals, so it didn’t drive demand. Great content, wrong narrative. When content is infrastructure, strategy fences that in. Topic selection pulls toward the solution, and visuals reinforce it right where buyers are deciding.
How do you regain control without hiring an army?
Codify the rules. Make voice, structure, visuals, links, and schema deterministic. Use a persistent knowledge base for facts and a Topic Universe for coverage. People supervise the system, not patch holes one by one. Small teams can absolutely publish daily like this. Not because they work harder, because they work inside guardrails.
The hard part isn’t agreeing on the rules. It’s enforcing them without creating bottlenecks. That’s why quality needs to be a gate with automatic remediation, not a doc of recommendations nobody opens. Once the system enforces the basics, your team reinvests time in narrative and originality.
Still fixing the same issues every week? Consider a different operating model. Try the system approach and see what changes.
The 8-Step System For Content As Infrastructure
The system looks like eight steps: persistent memory, coverage mapping, differentiation gates, snippet-ready structure, automated visuals, QA gates, deterministic linking and publishing, and continuous feedback. Each step is simple. Together, they remove chaos.
Step 1: Build a persistent knowledge base and brand memory
You can’t control quality without a single source of truth. Aggregate docs, product notes, positioning, and approved phrases. Then chunk, embed, and tag your sources so drafting pulls from facts, not guesses. Add voice constraints and banned terms so tone issues are caught at the gate.
Treat the KB like code. Version it. Review it. Keep it small enough to stay accurate and broad enough to cover product essentials. This gives your writers and your system the same ground truth. No more “which doc is current?” debates. Fewer worried-about moments with customers later.
Step 2: Map your Topic Universe and enforce cooldowns
Your Topic Universe is the strategy engine. Pull topics from the KB, your sitemap, and focus areas. Cluster by intent, then label clusters by saturation, Underserved, Healthy, Well-Covered, Saturated. Enforce a 90-day cooldown before you re-cover a topic. It’s a traffic guard, not a speed bump.
This does two things. First, it prevents over-publishing in one area while you starve others. Second, it gives you a shared language for prioritization. Decisions move out of spreadsheets and into a living system. You’ll ship more of the right things and fewer duplicates.
Step 3: Define information gain scoring and rejection rules
Before drafting, run competitive scans for the topic’s top coverage. Identify what’s common, what’s missing, and what’s shallow. Then compute an information gain score for your brief. Set a threshold. If it’s low, reject or remediate with specific prompts: add X case example, quantify Y, explain Z.
You’re not hunting for novelty for its own sake. You’re enforcing usefulness. Encode what “new” means for your brand, original data, unique frameworks, stronger examples. Give low-gain briefs a standard path to become high-gain. And if they can’t, park them. That discipline is what compounds.
Step 4: Create snippet-ready templates and deterministic structure
Every H2 should open with a 40-60 word, three-sentence direct answer. Paragraphs should be sized for featured snippets and clean AI references. Sections should stand alone with clear meaning. Schema rules should be baked in so search and assistants can parse your content reliably.
These aren’t creative limits. They’re retrieval contracts. When every section is citable, you increase eligibility for snippets and citations. Your content becomes referenceable, not just readable. And because the rules are deterministic, you don’t rely on a human to remember them at 4:45 pm.
Step 5: Automate visuals and asset placement
Centralize brand colors, marks, style references, and product screenshots. Generate on-brand hero and inline images automatically. Use semantic matching to place the right product screenshot beside the right section. Generate alt text and filenames programmatically. Prioritize solution sections for product visuals that actually matter.
This eliminates the “image scramble” after draft approval. It also prevents generic AI visuals that cheapen your brand. The goal isn’t pretty pictures. It’s credibility, showing the product where it counts, styled like you, every time. Not once. Always.
Step 6: Implement an automated QA gate with remediation loops
Make QA pass/fail. Define criteria across structure, voice, KB grounding, snippet readiness, visuals, alt text, internal links, and schema. Set a minimum score and require remediation loops that automatically fix common misses. If it doesn’t pass, it doesn’t move.
This removes personality-driven edits and replaces them with standards. Editors shift from fixing commas to improving narrative. Over time, quality becomes predictable. Rework drops. And you stop burning cycles on avoidable errors the system could’ve caught in seconds.
Step 7: Wire deterministic internal linking and publishing connectors
Inject internal links from a verified sitemap only. Match anchor text exactly to page titles. Place links at natural sentence boundaries. Then map CMS fields and enforce idempotent publishing so duplicates are impossible. Keep this whole layer code-based, not LLM-driven.
When the last mile is deterministic, you stop breaking things at the finish line. Links resolve. Schema validates. Publishing succeeds on the first try. Your team can finally stop firefighting the same issues and use that time to improve the next brief.
Step 8: Close feedback loops and optimize coverage continuously
Operate a living coverage dashboard. Track cluster states, cooldowns, and upcoming re-coverage windows. Feed publish outcomes back into your Topic Universe so tomorrow’s priorities reflect today’s state. Re-plan weekly, lightly. The system gets smarter because it listens to itself.
If you want another angle on setting up the scaffolding for this, this guide is a useful complement: Set up content infrastructure. The specifics vary by team. The principles tend to travel well.
How Oleno Operationalizes The 8-Step Pipeline
Oleno runs this system end to end. It builds topic strategy, enforces differentiation, structures for citation, generates brand visuals, injects links and schema deterministically, and delivers CMS-ready articles. You get execution, not another dashboard to manage.

Here’s how it works in practice. Topic Universe discovers and clusters topics from your KB and sitemap, tracks saturation, and enforces cooldowns so you don’t cannibalize yourself. Briefs include competitive research and Information Gain Scoring; low-gain outlines are flagged early with suggested fixes so you don’t ship another me-too piece. Drafts follow snippet-ready structure, and Brand Studio applies your voice constraints and banned terms so tone is consistent without manual police work.

Visual Studio generates brand-consistent hero and inline images, semantically matches product screenshots to relevant sections, and writes alt text and filenames automatically. After text and visuals finalize, deterministic internal links are injected from your verified sitemap, anchor text is matched exactly to page titles, and schema markup is generated programmatically. Publishing connectors map fields for WordPress, Webflow, or HubSpot and prevent duplicates by design. The QA gate evaluates 80+ criteria, structure, clarity, information gain, snippet readiness, visuals, and more, then loops refinements until standards are met.
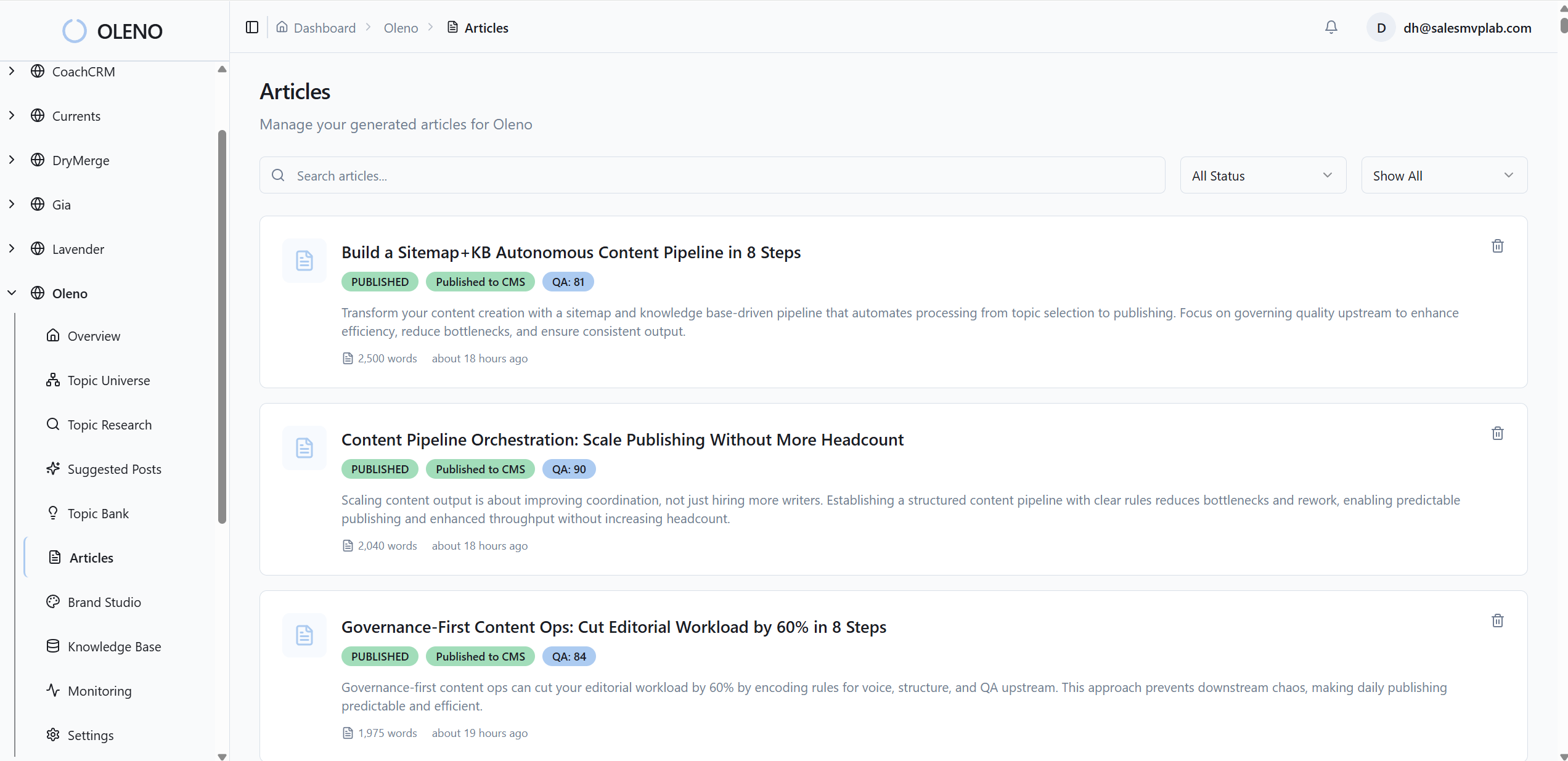
The result ties back to the earlier costs. Rework hours drop because quality is enforced upstream. Duplication and drift fade because Topic Universe and cooldowns gate what enters the pipeline. Publishing friction disappears because links, schema, and connectors are code, not manual effort. Want to see the system without committing your calendar? Try a light test. Prefer to skip the theory and see it run? Try Generating 3 Free Test Articles Now.
Conclusion
You don’t fix content chaos by writing faster. You fix it by running a system that remembers, enforces, and ships. Treat content like infrastructure, persistent memory, deterministic rules, continuous operations, and the work starts compounding. Fewer surprises. Fewer fixes. More authority.
If you’re still wrestling the same misses every week, you’re not alone. There’s a different way to operate. Still dealing with manual cleanups and drift? Try Using an Autonomous Content Engine for Always-On Publishing. And if you’re ready to experiment with your own topics and voice, you can Try Oleno For Free.
About Daniel Hebert
I'm the founder of Oleno, SalesMVP Lab, and yourLumira. Been working in B2B SaaS in both sales and marketing leadership for 13+ years. I specialize in building revenue engines from the ground up. Over the years, I've codified writing frameworks, which are now powering Oleno.
Frequently Asked Questions